Comparing the Class of 2020 and 2021 with Machine Learning and Reddit
Introduction
The college application process is stressful. Any student knows that it will be overwhelming even in the best of cases. On top of that, the many students that graduated high school in the past two years had another stressor that no one could have predicted: COVID-19. From missing out on their last year of high school to having trouble (both financial and academic) applying to their top-choice college, these students have had it bad. I, as part of the class of 2020, can attest to this. The coronavirus pandemic has caused much uncertainty and unexpected roadblocks in my college application process.
Even just between the class of 2020 and the class of 2021, the times have changed dramatically. Most schools have been able to partially reopen and we are seeing a return to ‘normalcy’ already (Operational). I first noticed this difference when talking to students in the class of 2021 who seemed to be both have a more typical senior year and also a more stressful one. These are seemingly juxtaposing, however. I am not the only one to notice this, either. The Tampa Bay Times interviewed 10 high school seniors on their experiences. Some said positive things about the year:
“‘I go to school every day, and I try to appreciate it, because last year when I didn’t have it, I was bored out of my mind,’ said Gavyn Dorsey, a senior at Zephyrhills High. ‘I treat every day like it’s the best day.’” (Tampa)
Others stated the negatives:
“‘I’m not going to lie. It hurts,’ said Jenesis Montero, a senior in Blake High School’s fine arts magnet program, who saw so many of her performances and competitions canceled. ‘I didn’t think they would take everything away. We have nothing. We have literally nothing.’” (Tampa)
It should be noted, however, that these ideas aren’t mutually exclusive. Any given student could both be upset because of the state of their senior year of high school while still being optimistic and appreciate what they still have. What interests me, however, is the difference between the class of 2020 and the class of 2021.
The rest of this article aims to figure this out as well as answering the question “what are the differences in attitudes in the class of 2021 compared to the class of 2020?”. To answer this, I took data from Reddit from the popular subreddits r/ACT, r/SAT, and r/ApplyingToCollege and analyzed it with the machine learning technique word2vec.
Why Reddit?
I chose Reddit for my corpus for three reasons: it is organized into subreddits, there are dates attached to posts, and posts are long (so the students can elaborate on their experiences more). Reddit is also a popular social media for posting about college applications. For example, r/ApplyingToCollege self-proclaims themselves as “the premier forum for college admissions” with 341,000 active members. Therefore, it acts as a great corpus for seeing the thoughts of students applying to colleges. I also gathered data from r/ACT and r/SAT as taking these exams is vital for the college application process. Although several schools got rid of their standardized testing requirements in light of the pandemic, these communities have still been very active.
For scrapping Reddit, I used praw which is an API in Python for getting information from Reddit. For the class of 2020, I considered all posts from the respective subreddits that fall between the dates of August 1st, 2019 to June 1st, 2020. For the class of 2021, the date range was just one year later: August 1st, 2020 to June 1st, 2021. This method does result in some spillover, such as ambitious freshmen and sophomores posting as well as those who like the linger on the subreddit after they are done with the application process. However, because these spillovers are uncommon, the data is still representative of the respective classes.
Python code used:
What is Word2Vec?
Word2Vec is a technique commonly used in natural language processing that assigns given words to a vector (which can have hundreds of dimensions). Essentially, it takes the meaning of a given word and maps it to a vector. Why is this helpful? Well, because vectors are just linear algebra, we can do math with them. We can see relationships between two word vectors to understand their semantic relationship. That is, we can see how similar words are by seeing how close they are in a vector space. For simplicity, you can think of it as a graph with points. The closer words are to each other on that graph, the closer their meanings are.
If we import the Reddit corpora into the word2vec package in the R programming language, we can visualize some of the data.
Here is the class of 2020:
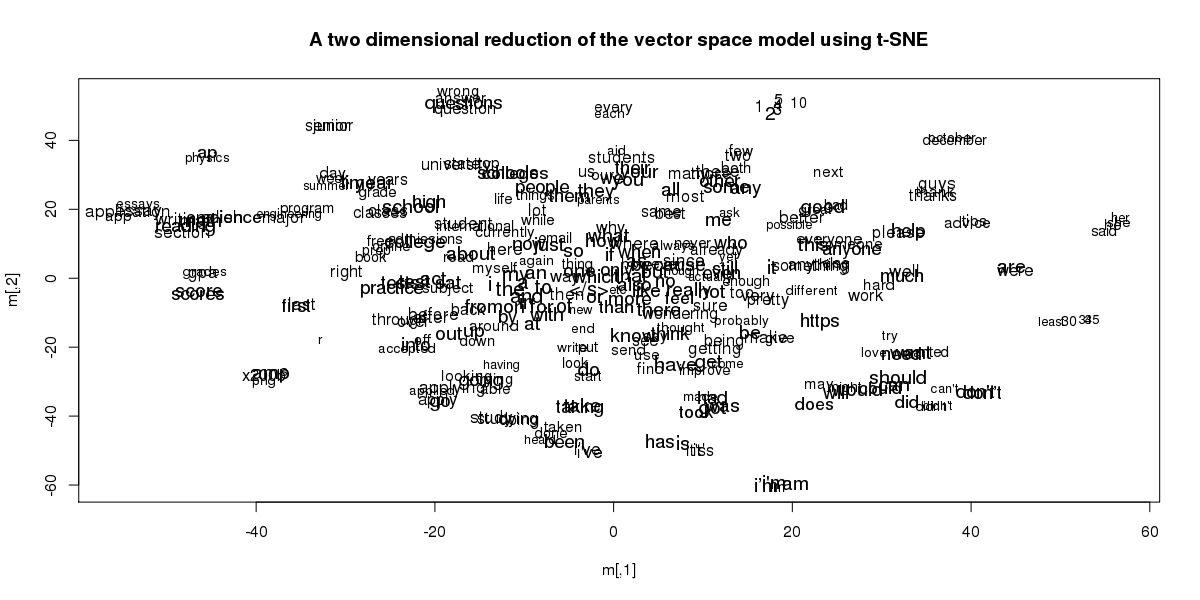
Here is the class of 2021:
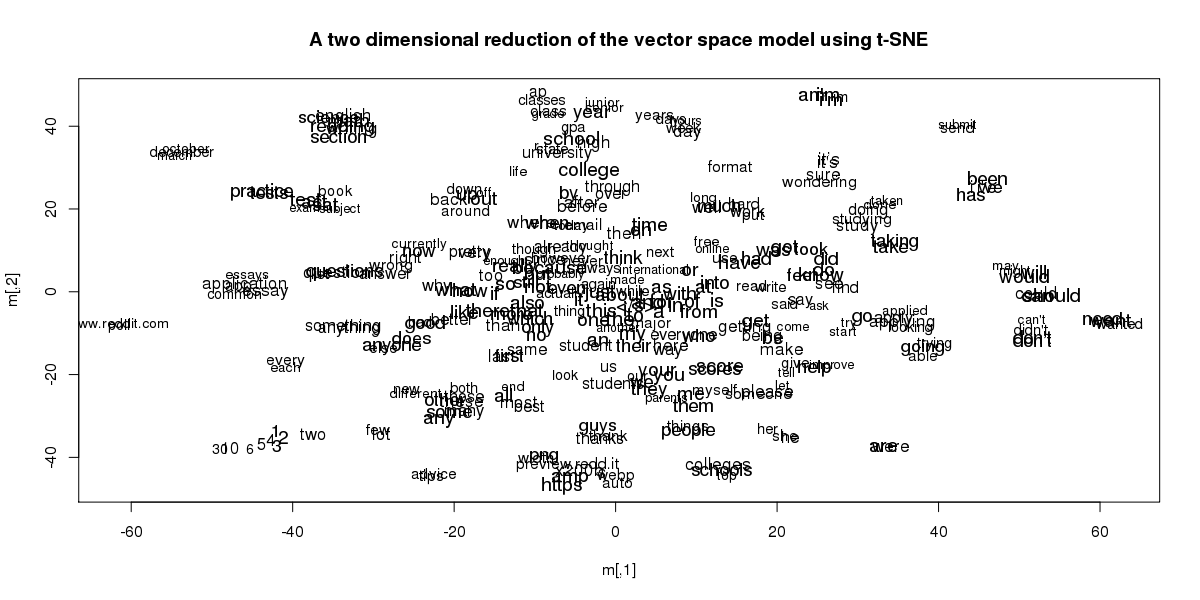
Keep in mind that the actual location of each word is arbitrary (which is why the numbers in the class of 2020 dataset are in a different location than the numbers of the class of 2021). It’s the relationships that are important.
The Results
I tried three different queries in both of the corpora to compare: uncertainty, covid, and stress. These results were then used to make conclusions about the different attitudes of the class of 2020 and the class of 2021.
Uncertainty
First, I wanted to see students’ thoughts regarding uncertainty. To do this, I found what words are most similar and related to ‘uncertain’ and ‘uncertainty’ by running the following R code:
classof2020 %>% closest_to(~"uncertain"+"uncertainty", 20)
This resulted in the following table:
| Class of 2020 | word | similarity to “uncertain” + “uncertainty” |
|---|---|---|
| 1 | uncertainty | 0.916201454249531 |
| 2 | uncertain | 0.800270770179415 |
| 3 | virus | 0.573571297177422 |
| 4 | pandemic | 0.563139000208725 |
| 5 | daunting | 0.537301285335967 |
| 6 | signs | 0.5355093861046 |
| 7 | concerns | 0.531550817807281 |
| 8 | excitement | 0.530166944442763 |
| 9 | surrounding | 0.515865066798079 |
| 10 | corona | 0.510703784331665 |
| 11 | midst | 0.509826727040499 |
| 12 | lockdown | 0.509195898826775 |
| 13 | dread | 0.505274784596487 |
| 14 | outcomes | 0.504228181962831 |
| 15 | stigma | 0.504088021311954 |
| 16 | unstable | 0.502606934423754 |
| 17 | coronavirus | 0.502527241517773 |
| 18 | expectation | 0.499880866941874 |
| 19 | outbreak | 0.498839683540765 |
| 20 | corners | 0.497746503311933 |
Already, you can notice how COVID-19 is present in 6 (bolded) of the top 20 similar words. For comparison, I also did this for the class of 2021 corpus. This yielded the following table:
| Class of 2021 | word | similarity to “uncertain” + “uncertainty” |
|---|---|---|
| 1 | uncertain | 0.806773534302534 |
| 2 | uncertainty | 0.784916186119596 |
| 3 | dreading | 0.654581549097321 |
| 4 | avoided | 0.613847350145064 |
| 5 | kicking | 0.605324004291105 |
| 6 | considerable | 0.591866339914577 |
| 7 | biased | 0.590763063424328 |
| 8 | sleeping | 0.587421351684044 |
| 9 | sacrificing | 0.580067895212026 |
| 10 | questioning | 0.579700939187577 |
| 11 | dedicating | 0.572807165602128 |
| 12 | frustration | 0.565102488262904 |
| 13 | schoolwork | 0.564671233956532 |
| 14 | unproductive | 0.563131848504995 |
| 15 | workload | 0.559043160869937 |
| 16 | impactful | 0.556937053741166 |
| 17 | individuals | 0.556410105374563 |
| 18 | situations | 0.555195834166442 |
| 19 | defeated | 0.553633837850615 |
| 20 | unhappy | 0.552352692912157 |
Surprisingly, no words relating to the coronavirus made their way to the top 20. From this, we can assume that the uncertainty of COVID-19 affected the class of 2020 significantly more than the class of 2021. Although this was expected, I was surprised how not a single COVID-19 related word appeared.
COVID-19
The second query that I tried was searching for words relating to COVID-19. For this, I used the R code:
classof2020 %>% closest_to(~"covid"+"coronavirus", 20)
That code resulted in the following table:
| Class of 2020 | word | similarity to “covid” + “coronavirus” |
|---|---|---|
| 1 | covid | 0.927010003808503 |
| 2 | coronavirus | 0.914407842634866 |
| 3 | pandemic | 0.756876875665945 |
| 4 | outbreak | 0.743696242619837 |
| 5 | 19 | 0.706524442613571 |
| 6 | cancellations | 0.614211640528429 |
| 7 | covid19 | 0.601072599310534 |
| 8 | virus | 0.599014496064918 |
| 9 | corona | 0.593752302818033 |
| 10 | situation | 0.54530106936663 |
| 11 | 4 | 0.540277552151175 |
| 12 | 3 | 0.534743280988726 |
| 13 | 9 | 0.532063589951454 |
| 14 | www.forbes.com | 0.529202532238379 |
| 15 | lining | 0.529023601531651 |
| 16 | 1 | 0.524257973963267 |
| 17 | crisis | 0.522048729073635 |
| 18 | 5 | 0.520963679829812 |
| 19 | www.nytimes.com | 0.51507740299426 |
| 20 | uncertainty | 0.513892154116675 |
The first two things that stick out in this table are the numbers and the URLs. The numbers are (mostly) specific dates of canceled events such as SAT or ACT test dates, and the URLs, www.forbes.com and www.nytimes.com, are popular sites that track the coronavirus. The exception is ‘19’ which is from the phrase “covid 19”. However, these numbers and URLs aren’t apparent in the class of 2021 version of the table as shown below:
| Class of 2021 | word | similarity to “covid” + “coronavirus” |
|---|---|---|
| 1 | covid | 0.927572248980337 |
| 2 | coronavirus | 0.925194258658541 |
| 3 | pandemic | 0.740656253763169 |
| 4 | capacity | 0.661856864633386 |
| 5 | corona | 0.637021535204168 |
| 6 | due | 0.626885755343254 |
| 7 | virus | 0.625887637395977 |
| 8 | cancelled | 0.578294801796821 |
| 9 | closed | 0.569695128455252 |
| 10 | 19 | 0.563720660535182 |
| 11 | lockdown | 0.549465196103793 |
| 12 | ongoing | 0.548434690854775 |
| 13 | restrictions | 0.547763706469807 |
| 14 | symptoms | 0.54383753952305 |
| 15 | adhd | 0.53999284844337 |
| 16 | canceled | 0.531780206224112 |
| 17 | caused | 0.516899057611585 |
| 18 | closures | 0.516884089588083 |
| 19 | circumstances | 0.513076732029396 |
| 20 | cases | 0.510760795339529 |
The closest words to “covid” in the class of 2021’s corpora are less relating to the virus itself and more on the effects of it – mainly the cancelations. By this, I can assume that the class of 2021 views COVID-19 as a fact of nature instead of a new phenomenon that is a cause of uncertainty.
Stress
The last query that I did was looking at the word ‘stress’. For this, the R command is:
classof2020 %>% closest_to("stress", 20)
The table for the class of 2020 is below.
| Class of 2020 | word | similarity to “stress” |
|---|---|---|
| 1 | stress | 1 |
| 2 | draining | 0.569763099756746 |
| 3 | anxiety | 0.568005619428719 |
| 4 | sleep | 0.556364373828751 |
| 5 | fear | 0.550306141962488 |
| 6 | intense | 0.549747369306958 |
| 7 | nerves | 0.546825651072332 |
| 8 | pressure | 0.533962601407304 |
| 9 | excitement | 0.532409821161514 |
| 10 | disappointment | 0.528782449520114 |
| 11 | emotionally | 0.510667143930341 |
| 12 | healthy | 0.504236970335187 |
| 13 | nerve | 0.502928272110659 |
| 14 | packed | 0.502672347198466 |
| 15 | existence | 0.501582095144679 |
| 16 | tears | 0.498361680102606 |
| 17 | uncertainty | 0.497733288854682 |
| 18 | relieve | 0.495661310995123 |
| 19 | hanging | 0.494759334664189 |
| 20 | boredom | 0.489887012525981 |
The class of 2021’s corpus yielded the following table:
| Class of 2021 | word | similarity to “stress” |
|---|---|---|
| 1 | stress | 1 |
| 2 | anxiety | 0.660850386058463 |
| 3 | yourselves | 0.565706189106917 |
| 4 | depression | 0.544819958947775 |
| 5 | urself | 0.538460151624733 |
| 6 | pressure | 0.534360784364564 |
| 7 | validation | 0.532770108129177 |
| 8 | stressing | 0.524595133499214 |
| 9 | fear | 0.524493787139435 |
| 10 | shit | 0.510227388359591 |
| 11 | workload | 0.508394797155711 |
| 12 | worry | 0.508108730036202 |
| 13 | control | 0.507477160961492 |
| 14 | severely | 0.499121925311335 |
| 15 | guilt | 0.48888089537924 |
| 16 | burnt | 0.486868788031278 |
| 17 | merry | 0.485100059230911 |
| 18 | fears | 0.479196256885631 |
| 19 | stressed | 0.47693203784829 |
| 20 | forget | 0.475067958970451 |
These results surprised me. I was originally thinking that both the graduating classes would have different similar words relating to “stress” because I assumed that the stress relating to new, unknown coronavirus would look different from the more predictable stressors of the college application process. These tables, however, are strikingly similar. The only notable difference is that the class of 2020’s table had the word “uncertainty”, which is expected in the time that COVID-19 was new. This word, however, is only the 17th closest word so it’s not that drastic of a difference.
Conclusion
The differences between graduating classes weren’t as stark as I initially thought. Although there were some clear differences relating to COVID-19 and uncertainty, the overall stress of the students were described similarly. This finding just goes to show how the college application process is relatively stable. So although both the class of 2020 and class of 2021 had vastly different college application processes, the attitudes were relatively similar.
If I were to do further research on this topic, I would like to explore more specifics. For example, I would clean the data to remove all websites that linked to either photo or Reddit itself so I could compare the usage of other college-related web pages across the years. I would also focus on the differences in elite compared to non-elite institutions. How was the process of applying to elite (and non-elite) schools different than in previous years? Lastly, I would explore the different majors and career paths. Are more people attracted to medical programs since the COVID-19 pandemic hit?
Works Cited
“Operational Strategy for K-12 Schools through Phased Prevention.” Centers for Disease Control and Prevention, Centers for Disease Control and Prevention, 19 Mar. 2021, www.cdc.gov/coronavirus/2019-ncov/community/schools-childcare/operation-strategy.html.
Tampa Publishing Company. “’Not Going to Lie. It Hurts.’ Class of 2021 Tries to Stay Positive.” Tampa Bay Times, 1 Feb. 2021, www.tampabay.com/news/education/2021/02/01/not-going-to-lie-it-hurts-class-of-2021-tries-to-stay-positive/.